
Data Soup
Winning tickets were discovered in March 2018 and presented at ICRL the same year. It drawed a lot of attention. It sheds light on yet unknown underlying properties of neural networks and seems to be one of the keys for faster training and smaller models. Overall flipping on the head how we approach neural net architecture design.
Winning tickets in deep learning were mentioned as one of the most important topics of 2019 by Lex Fridman’s in his Deep Learning State of the Art 2020 (awesome) lecture. This article aims at summarizing what I understood after reading about it. Hope you’ll enjoy it.
It is known that DL models have generally heavy computational requirements and can be blocking in particular settings. ResNet, for instance, requires 50M operations for one single inference. They’ve been efforts to reduce the number of parameters with quantization, knowledge distillation and pruning.
Pruning removes the least important weights or channels. Least important can mean the one with the smallest magnitudes or other heuristics. Such a technique is working well and can reduce up to 90% of the weights in a network while preserving most of the original accuracy. While pruning can help to reduce the model’s size, it won’t help training it faster. It is generally a post-processing step, after training. Retraining a pruned model won’t yield the same results as if you prune after training. If it were possible to be able to train the pruned model directly, train faster without sacrificing performances.
But in their paper Jonathan Frankle, Michael Carbin experimentally found that instead of training large networks and then reduce their size we might be able to train smaller networks upfront:
dense, randomly-initialized, feed-forward networks contain subnetworks (“winning tickets”) that - when trained in isolation - reach test accuracy comparable to the original network in a similar number of iterations.
In order to find winning tickets, initialization seems to be the key:
When their parameters are randomly reinitialized […], our winning tickets no longer match the performance of the original network, offering evidence that these smaller networks do not train effectively unless they are appropriately initialized.
They found that we can train a pruned model again after re-initializing the weights with the original model’s parameters. This gives systematically better results than re-initializing randomly. Doing this process multiple times is called iterative pruning (with no re-init):
1. Randomly initialize a neural network [with weights θ0]
2. Train the network for j iterations, arriving at parameters θj
3. Prune [by magnitude] p% of the parameters in θj , creating a mask m
4. Reset the remaining parameters to their values in θ0
5. Goto 2
If the subnetwork produced by this technique matches the original network’s performances, it is called a winning ticket. The following graph represents averaged results of five runs on a LeNet (fully dense) network on the MNIST dataset. This model was pruned in different ways:
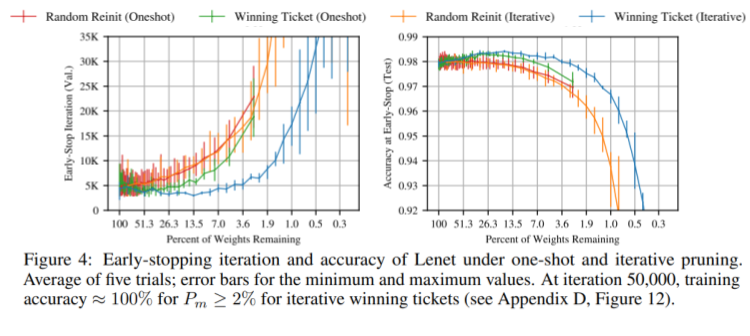
We can see that step 4 is the key as the green and blue lines are consistently performing better and are trained faster than randomly re-initialized networks. They also found similar results with convolutional networks like VGG and ResNet on MNIST and CIFAR10 (there are many more details in the original paper).
But the method above seems to struggle against deeper networks. In a follow-up paper (March 2019), the authors changed slightly the way the remaining parameters are reset (step 4):
Rather than set the weights of a winning ticket to their original initializations, we set them to the weights obtained after a small number of training iterations (late resetting). Using late resetting, we identify the first winning tickets for Resnet-50 on Imagenet.
The graph below plot performances against different levels of sparsity of deep models rewound (iteration at which we reset the weights) with different values. We can see that rewinding at iteration 0 does not perform better than the original network whereas rewinding at higher iteration does:
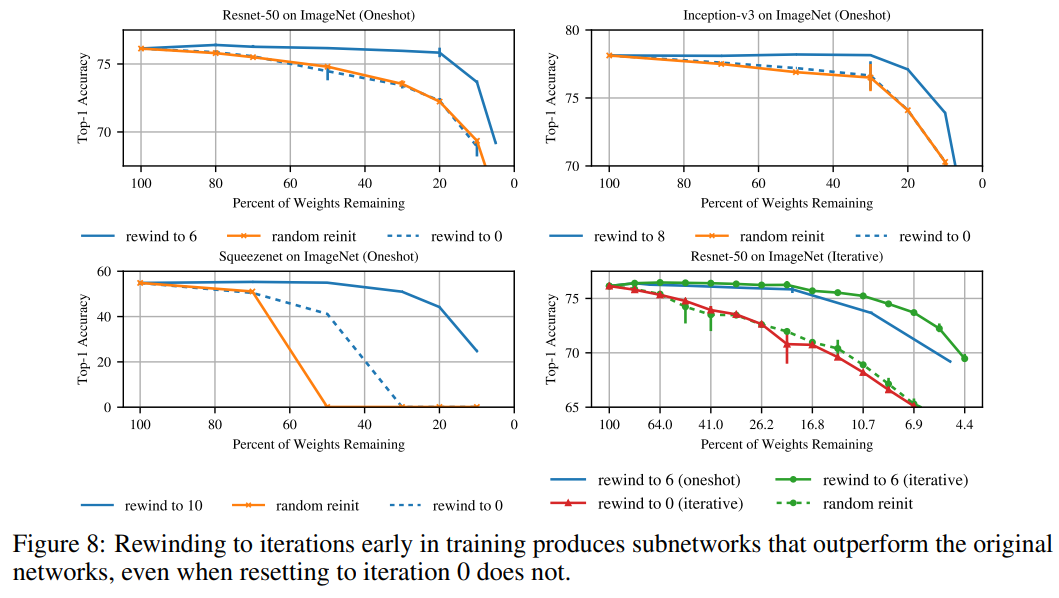
Those deeper models were resisting the winning ticket recipe above but found something interesting after looking at their stability:
The table below shows stability for different networks. Warmup means that the learning rate is scheduled to increase slowly during training, possibly reducing the noise of the optimizer. IMP is the original recipe to generate winning tickets:
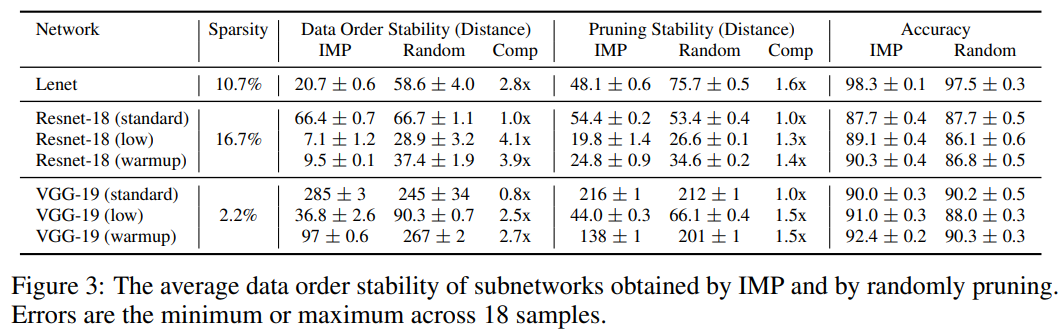
We can see that IMP fails at fiding winning tickets in deeper networks without changing the learning rate. We can also see that there’s a link between performances and the stabilities measures. “Winning tickets are more stable than the random subnetworks”.
So far winning tickets have been tested on the same datasets and on computer vision tasks. One can ask if this isn’t just drastic overfitting or if the winning tickets transfer at all.
Facebook published a paper (June 2019) tested the winning ticket evaluation and transfer across six visual datasets. For instance, testing generating winning tickets on ImageNet and testing it others (like CIFAR-100):
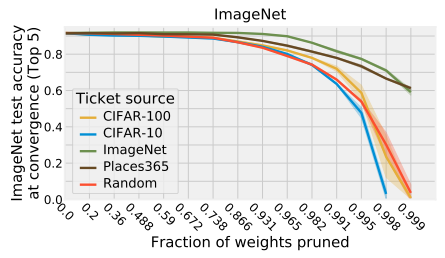
They observed that winning tickets generalize across all datasets with (at least) close performances than the original one. And that winning tickets generated on larger datasets generalized better than the other ones, probably due to the number of classes in the original model. Finally, this paper also tested the transfer successfully across different optimizers successfully.
What about other tasks than image classification? Facebook published in parallel a paper (June 2019) that test the winning ticket in reinforcement learning and NLP tasks.
For NLP, we found that winning ticket initializations beat random tickets both for recurrent LSTM models trained on language modeling and Transformer models trained on machine translation. […] For RL, we found that winning ticket initializations substantially outperformed random tickets on classic control problems and for many, but not all, Atari games.