
Data Soup
This is a summary of Stiffness: A New Perspective on Generalization in Neural Networks.
This paper aims at improving our understanding of how neural networks generalize from the point of view of stiffness. The intuition behind stiffness is how a gradient update on one point affects another:
[it] characterizes the amount of correlation between changes in loss on the two due to the application of a gradient update based on one of them. (4.1, Results and discussion)
Stiffness is expressed as the expected sign of the gradients g:
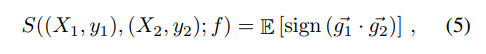
A weight update that improves the loss for X_1 and X_2 is stiff and characterized as anti-stiff if the loss beneficiate for one of the points and doesn’t help the other.
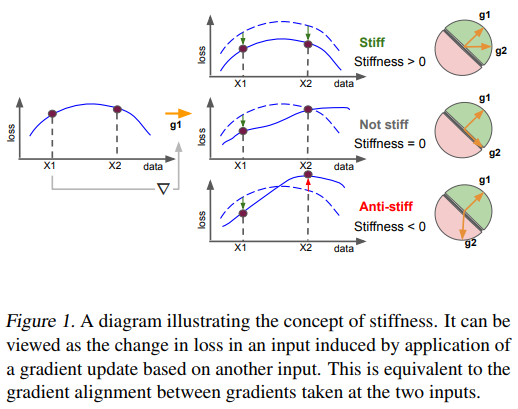
The question is now how do we choose X_1 and X_2. Authors explore two ways: by class membership or by distance.
We can look at how a gradient update on a point in class A will affect another point’s loss belonging to class B. In the paper they craft a *class stiffness matrix`, which is the average of stiffness between each point grouped by class:
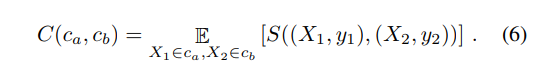
The diagonal of this matrix represent the model’s within class generalization capability. You can find an example of stiffness class matrix at different steps of the training stage:
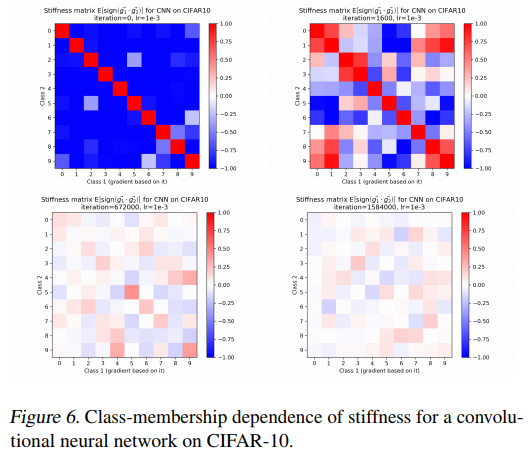
At early stages, the stiffness is high between members of the same classes (hence the red diagonal). The majority of the cells raises their stiffness until reaching the point of overfitting: stiffness reaches 0.
Stiffness is then studied through the distance lens, they distinguish two kinds of distance: pixel-wise (in the input space) and layerwise (in the representational space).
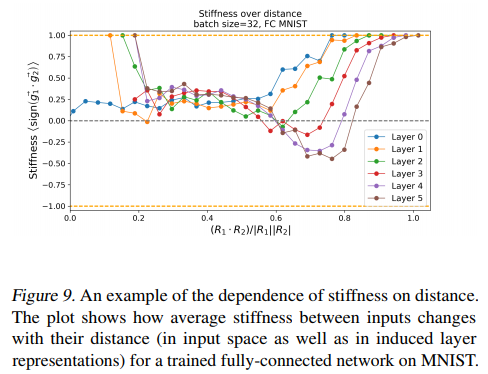
The general pattern visible in Figure 9 is that there exists a critical distance within which input data points tend to move together under gradient updates, i.e. have positive stiffness. This holds true for all layers in the network, with the tendency of deeper layers to have smaller stiff domain sizes.
Authors define stiff regions as “regions of the data space that move together when a gradient update is applied”.
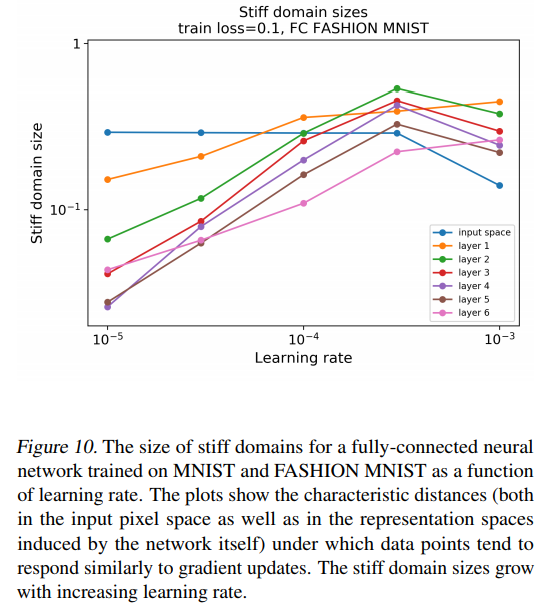
We can see that a higher learning rate increase the size of the stiff regions which suggests that higher learning rates help generalization.
| Author | Organization | Previous work |
|---|---|---|
| Stanislav Fort | Google AI Resident, Google AI Zurich | The Goldilocks zone: Towards better understanding of neural network loss landscapes |
| Paweł Krzysztof Nowak | Google AI Resident | |
| Srini Narayanan | Google AI Resident |
Complementary resources: