
Data Soup
Knowledge distillation is a fascinating concept, we’ll cover briefly why we need it, how it works.
Today’s models can be quite large, here are some of the top models for the ImageNet dataset:
| Model | Weights (millions) | Size (32-bits floats) | Size (16-bits floats) |
|---|---|---|---|
| MobileNet-224 | 4.3 | 17.2 Mo | 8.6 Mo |
| VGG16 | 143.7 | 574.8 Mo | 287.4 Mo |
| InceptionV3 | 23.9 | 95.6 Mo | 47.8 Mo |
| ResNet-50 | 25.6 | 102.4 Mo | 51.2 Mo |
| InceptionResNetV2 | 55.9 | 223.6 Mo | 111.8 Mo |
The models were instantiated via keras.applications module with top layers, the number of parameters are given by summary().
It seems fair to say that simple computer vision models weigh easily ~100Mo. A hundred Mo just to be able to make an inference isn’t a viable solution for an end product. A remote API can do the trick, but now your product needs to add encryption, you need to store and upload data, the user needs to have a reliable internet connection to have a decent speed. We can train a narrower network, they’ll probably fit in a small memory. But chances are they won’t be good enough at extracting complex features.
And we’re not talking about ensembles. Ensembles are a great way to extract a lot of knowledge from the training data. But at test time it can be too expensive to run a hundred different models in parallel. The knowledge per parameter ratio is quite low.
In the end a model can have great score at training time, but we might want to: lower its size (for embedded systems), increase inference speed or simply reduce complexity. Geoffrey Hinton talks about reducing its “memory foot print”:

Many insects have a larval form that is optimized for extracting energy and nutrients from the environment and a completely different adult form that is optimized for the very different requirements of traveling and reproduction. In large-scale machine learning, we typically use very similar models for the training stage and the deployment stage despite their very different requirements (…) (Distilling the Knowledge in a Neural Network)
Training a smaller model from a larger one is called knowledge distillation.
The authors continue that we are identifying knowledge with the values of the weights which makes it “hard to see how we can change the form of the model but keep the same knowledge”. And remind us that we can see knowledge as a mapping from input to output.
Knowledge distillation’s goal is to transfer the learning from one performant and heavy teacher to a more compact student.
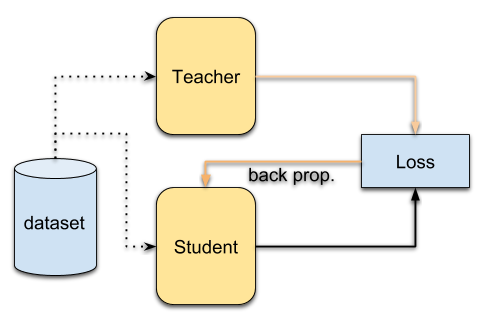
To do so, we look at the teacher’s softmax layer, magnify it and the student learns how to produce them. We need to magnify because the softmax layer will smash down to zero the least probable classes and rises close to one the most probable (like one hot vector). We can also keep the relative probabilities between classes, where a motocycle and a bicycle share more similarities on the softmax layer rather than a book. We can do it by raising the temperature T.
To transfer knowledge, a student is trained on the soften probabilities (T»1) produced by a larger teacher. When the temperature T is smaller than one, the most expected classes will impact the most the final probability. Similarly, when increasing the temperature the probabilities will be softer/flattened across classes -you can have here an intuition of the influence of temperature on a single exp().
First the teacher’s temperature is increased until a certain point. Then the student is trained to copy its teacher’s soft probabilities.
| labrador | cow | golden retriever | moto | bike | |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | hard targets |
| 0.8 | 10^-5 | 0.2 | 10^-9 | 10^-9 | soft targets (T=1) |
| 0.6 | 10^-2 | 0.45 | 10^-4 | 10^-4 | soft targets (T»1) |
Training on soft targets has several advantages: more information can be extracted from a single sample, training can be done on fewer examples, no need for labeled data
The softmax of a multi-class classifier will give you higher probabilities for similar images. A rose may have similar soft probabilities with a tulip rather than a labrador. Similarly, two different classes are present in the same image, we might see it on the output. So more information are extracted from each training sample.
This is a consequence from the first point, the model can be trained on fewer training examples than the teacher. The learning is also faster because there are more constraints on the student. It needs to target multiple (soft) outputs rather than a single (hard) one.
Since the student learns from soft targets only, by relative similarities between classes, it can be trained on a unlabelled dataset, using only the master has an on-fly “soft labeler”. But in practice, the dataset can be the same as the teacher.
Distillation loss is generally in two forms: matching function values, matching derivatives or both, corresponding to a regression problem with different orders:
Matching function values: tries to minimize the difference between the predictions of the teacher and the student. For a classification task, this is done by using classical cross entropy.
Matching derivatives: tries to match the values and the derivatives. This is a more efficient approach than before because here we can have full access to the teacher and we are able to measure the impacts of small variations in its inputs.
We can also try to increase the influence of the prediction by adding directly the hard loss:
alpha ~= 0.1
KD_loss = alpha * log_loss(y_true, softmax(logits)) + logloss(y_true, softmax(logits/temperature))
You can see a cool implementation here.
TTIC Geoffrey Hilton - Dark Knowledge - presentation by the author of the first Knowledge Distillation paper
IEE Security Symposium, Papernot: Note that the distillation as a counter measure for adversarial examples has been proven to be not effective anymore.